商务信息咨询项目如何选择 五大必知大数据处理框架技术对比分析

在当今数据驱动的商业环境中,商务信息咨询项目能否高效处理海量数据,直接决定了洞察的深度与决策的准确性。面对众多大数据处理框架技术,如何选择最适合自身项目的工具,成为咨询团队的核心考量。本文将深入剖析五种主流大数据处理框架技术,并从商务信息咨询的应用场景出发,为您提供清晰的选型指南。
一、五大必知大数据处理框架技术概览
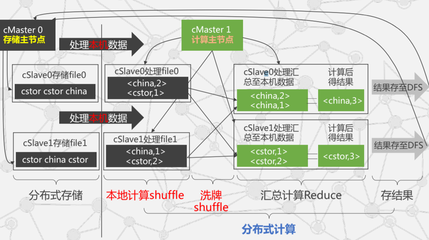
- Apache Hadoop:作为大数据领域的基石,Hadoop以其分布式文件系统(HDFS)和MapReduce计算模型闻名。它擅长离线批处理,适合处理历史业务数据、生成周期性报告,例如对过去一年的市场趋势进行宏观分析。
- Apache Spark:凭借内存计算优势,Spark在批处理、流处理及机器学习等领域表现卓越。其速度远超Hadoop,适合需要实时或近实时分析的场景,如动态监测市场舆情、快速验证商业假设。
- Apache Flink:作为真正的流处理框架,Flink支持事件驱动型应用,可实现极低延迟的数据处理。对于需要即时响应的咨询项目,如金融风险实时监控或供应链异常检测,Flink是理想选择。
- Apache Kafka:严格而言,Kafka是一个分布式事件流平台,常作为数据管道用于高吞吐量的实时数据集成。在咨询项目中,它可用于连接多源数据(如CRM、社交媒体),确保数据流动的可靠性与时效性。
- 云原生服务(如AWS EMR、Google BigQuery):各大云平台提供的托管服务,降低了运维复杂度。对于资源有限或追求敏捷的咨询团队,这些服务能快速部署,灵活伸缩,适合短期或试点项目。
二、商务信息咨询项目的选型关键因素
- 数据特性:
- 若数据以静态历史数据为主(如年度财务审计),Hadoop或Spark批处理模式更为经济。
- 若涉及高速流数据(如实时交易日志),应优先考虑Flink或Spark Streaming。
- 业务时效性要求:
- 对实时决策依赖强的项目(如竞争情报动态分析),需采用Flink或Kafka+Spark组合。
- 对时效要求宽松的深度分析(如行业长期趋势预测),Hadoop或Spark批处理已足够。
- 团队技术能力:
- Hadoop生态成熟但学习曲线陡峭,适合有深厚技术积淀的团队。
- 云原生服务简化了运维,更适合技术资源紧张或追求快速迭代的咨询团队。
- 成本与可扩展性:
- 自建集群(如Hadoop/Spark)前期投入大,但长期定制性强。
- 云服务按需付费,适合业务量波动大的咨询项目,能有效控制成本。
三、实战选型建议:匹配咨询场景
- 场景一:市场进入策略咨询
需要整合多年行业数据与宏观经济指标,进行批量建模分析。推荐使用Spark,平衡处理效率与复杂性,并借助MLlib库进行预测分析。
- 场景二:客户体验实时优化咨询
需处理来自网站、APP的实时用户行为数据,即时识别痛点。推荐采用Kafka收集数据流,由Flink进行实时处理与告警,实现秒级洞察。
- 场景三:规模化数据平台建设咨询
为企业客户设计长期数据架构时,可结合Hadoop(存储与批处理基础)与Spark(高性能计算),构建混合框架以应对多样化需求。
- 场景四:敏捷型专项咨询
项目周期短、需求多变,建议直接采用云服务(如BigQuery),无需基础设施管理,专注分析逻辑与交付速度。
商务信息咨询项目选择大数据处理框架时,应摒弃“技术至上”思维,紧密围绕业务目标、数据特质与资源约束进行权衡。对于多数咨询团队,从Spark入手是一个稳健的起点,它在性能、生态与学习成本间取得了良好平衡。随着项目深入,可逐步引入Kafka、Flink等组件构建混合架构,最终形成贴合自身业务流的数据处理能力,从而在数据洪流中提炼出真正驱动商业价值的决策智慧。
如若转载,请注明出处:http://www.chelianefu.com/product/45.html
更新时间:2026-06-18 23:35:38