大数据处理技术 从数据洪流中提炼价值的核心技艺

在当今信息爆炸的时代,大数据已成为驱动社会进步和商业创新的关键燃料。而大数据处理技术,正是将原始、海量、异构的数据转化为有价值信息和洞见的系统化方法与工具集。它并非单一学科,而是一个融合了计算机科学、统计学、数学和应用领域知识的综合性技术体系。要掌握这门核心技术,究竟需要学习什么呢?其核心正是围绕 “数据处理” 这一生命线展开的多个层面。
一、 基础理论与架构认知
这是学习的起点,旨在构建对大数据生态的宏观理解。
- 大数据核心特征(4V+):深刻理解Volume(海量)、Velocity(高速)、Variety(多样)、Value(低价值密度)以及Veracity(真实性)等特征,是设计所有处理方案的前提。
- 分布式系统原理:大数据处理离不开分布式计算。需要学习分布式文件系统(如HDFS的设计思想)、集群管理、容错机制、以及计算如何向数据迁移而非相反的核心哲学。
- 主流处理框架与范式:掌握批处理(如Apache Hadoop MapReduce)、流处理(如Apache Flink, Apache Storm)、交互式查询(如Apache Hive, Presto)以及图处理等不同计算范式的适用场景与基本原理。
二、 数据处理的核心技能栈
这是技术学习的重中之重,贯穿数据从“原材料”到“成品”的全过程。
- 数据采集与集成:学习如何从数据库、日志、传感器、社交媒体等异构源实时或批量采集数据,涉及工具如Flume, Kafka, Sqoop等,并理解ETL(抽取、转换、加载)流程。
- 数据存储与管理:根据数据结构和访问模式,选择合适的存储方案,包括分布式文件系统、NoSQL数据库(如HBase, Cassandra)、NewSQL数据库、以及云存储服务。
- 数据计算与加工:
- 批处理编程:深入掌握MapReduce编程模型,以及更上层的工具如Hive SQL、Spark SQL(使用DataFrame/Dataset API)进行大规模数据集的分析。
- 流处理开发:学习处理无界数据流,实现实时监控、预警和分析,掌握窗口、状态、时间语义等核心概念。
- 图计算与机器学习:了解基于大数据的图算法和机器学习库(如Spark MLlib)的应用。
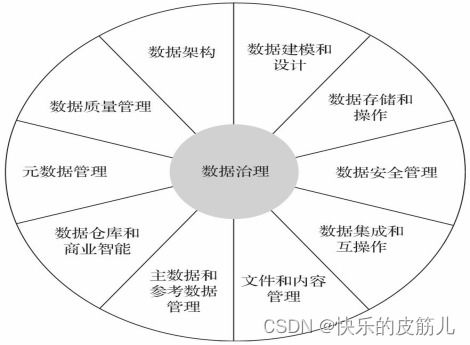
- 数据质量与治理:确保数据的准确性、一致性、完整性和时效性,学习数据清洗、去重、标准化、以及元数据管理、数据血缘追踪等技术。
三、 编程语言与工具生态
1. 核心编程语言:Java/Scala 是Hadoop/Spark生态的基石,Python 凭借其丰富的数据科学生态(Pandas, NumPy, PySpark)成为数据分析和机器学习的首选,SQL 是进行数据查询和操作的通用语言,必须精通。
2. 生态工具链:熟悉以Apache Hadoop/YARN/Spark/Flink为核心的整个开源生态,以及云平台(如AWS EMR, Azure HDInsight)提供的托管服务。了解资源调度器(YARN, Kubernetes)、协调服务(ZooKeeper)等支撑性组件。
四、 进阶与跨界能力
1. 性能调优与故障排查:学习如何对作业进行性能优化(如数据倾斜处理、内存调优、并行度调整),并具备集群和作业级别的故障诊断能力。
2. 数据仓库与建模:理解维度建模(星型、雪花模型)、数据分层(ODS, DWD, DWS, ADS)、以及现代数据湖仓一体(Lakehouse)架构。
3. 与数据分析和AI的衔接:明确大数据处理是为下游的数据分析、商业智能(BI)和人工智能(AI)模型训练提供高质量、可用的数据平台。需要了解基本的统计知识和机器学习流程。
4. 系统设计与架构能力:能够根据业务需求,设计高可用、可扩展、成本效益合理的大数据处理平台架构。
而言,学习大数据处理技术,是一场以 “数据处理” 为核心的深度旅程。它要求从业者既要有扎实的分布式系统理论基础,又要具备解决实际数据管道(从接入、存储、计算到输出)中各种工程问题的实战能力,同时还需对不断演进的技术生态保持敏感。最终目标,是成为一名能够驾驭数据洪流,为企业构建高效、可靠数据价值生产线的工程师或架构师。
如若转载,请注明出处:http://www.chelianefu.com/product/47.html
更新时间:2026-06-18 03:10:50